
Möglichkeiten von KI-Agenten
Generative KI-Agenten (GenAI Agents) können komplexe Denkprozesse, Entscheidungslogiken und multimodale Aufgaben automatisieren – etwa im Kundenservice, in der Softwareentwicklung, bei der Informationsbeschaffung oder der Orchestrierung von Workflows.
Diese Agenten verfügen über Fähigkeiten wie Planung, Reflexion sowie Kurz- und Langzeitgedächtnis, um frühere Interaktionen gezielt einzubeziehen. Sie können auch externe Tools wie Taschenrechner oder Websuche einbinden, um ihre Leistung zu verbessern.
In diesem Beitrag zeigen wir anhand eines Praxisbeispiels, wie wir mit der Low-Code-Plattform Dify einen Market Research Agent aufgebaut haben. Wir stellen unseren Workflow vor und teilen zentrale Learnings aus dem Projekt.
Was ist ein Agent für Marktforschung?
Ein KI-Agent für Marktforschung ist eine spezialisierte Form eines Deep-Research-Agents – ähnlich wie sie von Unternehmen wie OpenAI, Perplexity oder Jina AI entwickelt werden.
Ein solcher Agent verarbeitet komplexe Anfragen wie:
„Analysiere die KI-Strategie und Ambitionen von Unternehmen X – mit Fokus auf Daten, ...“
Daraufhin durchsucht der Agent systematisch das Web, identifiziert relevante Informationen und erstellt einen strukturierten Marktbericht.
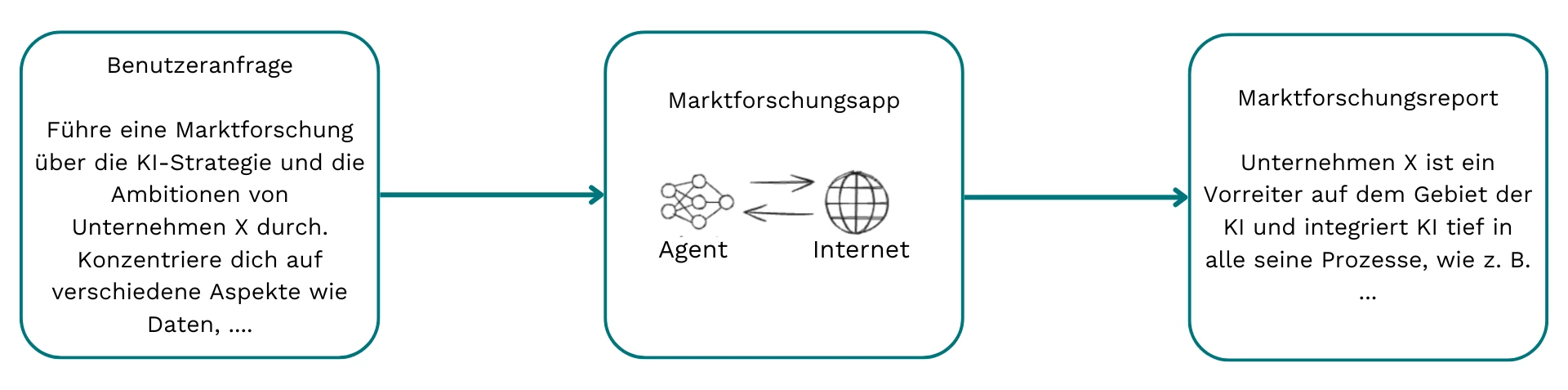
Ein leistungsfähiger KI-Agent für Marktforschung muss mehrere zentrale Aufgaben erfüllen:
- Die Nutzeranfrage verstehen und einen strukturierten Aktionsplan erstellen
- Relevante Informationen recherchieren – inklusive gezielter Suchanfragen
- Ergebnisse bewerten und sinnvolle Folgefragen ableiten
Dabei bleibt entscheidend, dass der Agent stets das Ziel im Blick behält und die ursprüngliche Anfrage nicht aus den Augen verliert – nur so entsteht ein fundierter, zielgerichteter Report.
Ebenso wichtig: Alle Aussagen im Bericht sollten nachvollziehbar und durch belastbare Quellen belegt sein.
Ausgehend von diesen Anforderungen haben wir uns für einen Divide-and-Conquer-Ansatz entschieden, den wir im nächsten Abschnitt vorstellen.
Unser Divide-and-Conquer-Ansatz
Wir haben einen Divide-and-Conquer-Ansatz gewählt, bei dem wir die komplexe Aufgabe in drei klar definierte Schritte unterteilt haben:
- Ausarbeitung & Planung
Basierend auf der ursprünglichen Nutzeranfrage wird diese geschärft und erweitert. Daraus entsteht eine strukturierte Liste relevanter Fragen, die für die Analyse beantwortet werden müssen. - Gezielte Recherche
Für jede dieser Fragen führen wir mithilfe verschiedener Tools mehrere Websuchen durch und sammeln Informationen aus unterschiedlichen Quellen. Daraus erstellen wir kompakte Faktenblätter mit Schlüsselzitaten und relevanten Metadaten. - Zusammenführung & Bericht
Die erarbeiteten Faktenblätter dienen als Grundlage für eine gegliederte Berichtsskizze, aus der der finale Marktforschungsreport entsteht – inklusive Quellennachweise und inhaltlicher Struktur.

Phase 1: Ausarbeitung und Planung
Ziel dieser Phase ist es, eine präzise Liste geschäftsrelevanter Forschungsfragen zu entwickeln, die die Nutzeranfrage bestmöglich abbilden. Der Ablauf orientiert sich am Prinzip reflektierter Iteration.
Zu Beginn wird die ursprüngliche Anfrage überarbeitet – mit Fokus auf Klarheit, Grammatik, Kohärenz und Lesbarkeit. So lassen sich Intention und Kontext des Nutzers besser erfassen.
Im nächsten Schritt wird die Anfrage in strukturierte, geschäftsorientierte Fragen überführt, die zentrale Themen und Konzepte gezielt aufgreifen. Diese bilden die Grundlage für die spätere Analyse.
Abschließend werden die Fragen priorisiert – je nach Relevanz für das Ausgangsziel und mit der Möglichkeit, die Liste bei Bedarf zu kürzen.
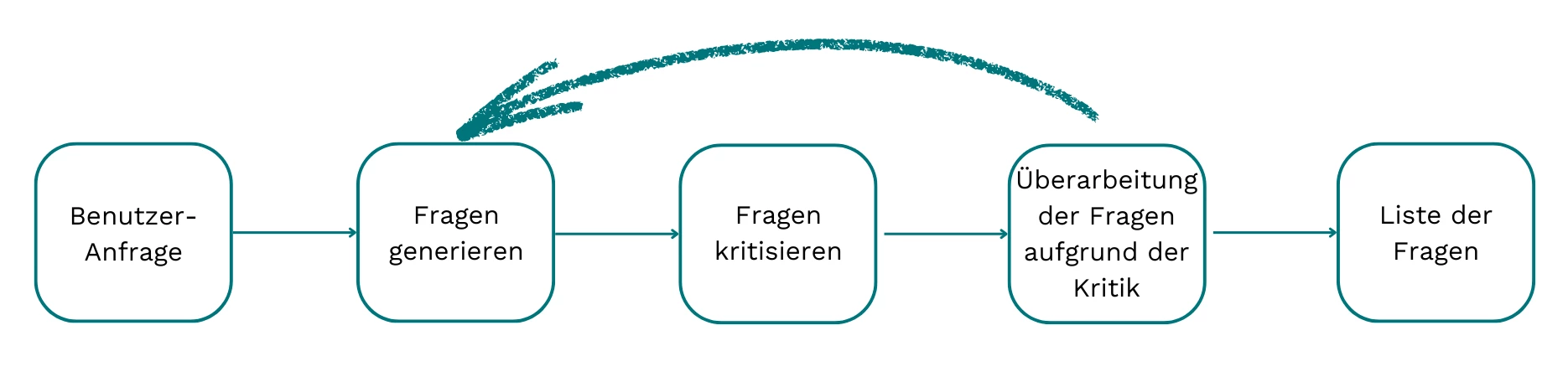
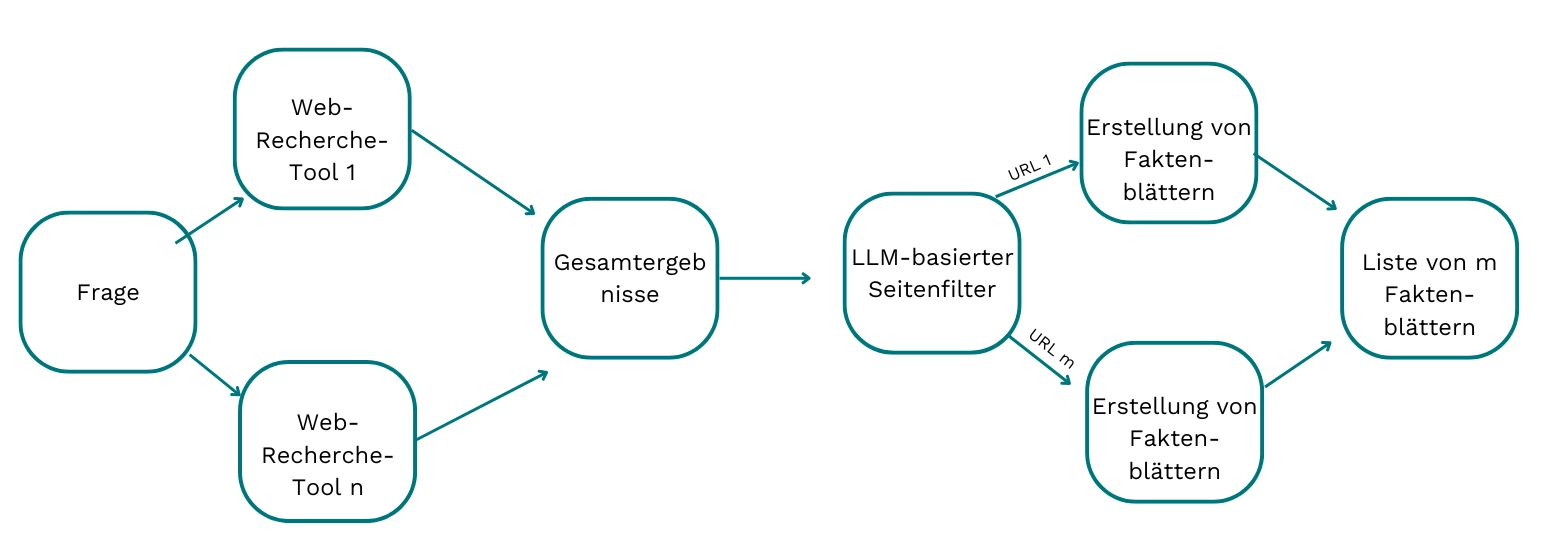
Phase 2: Tiefgehende Recherche
In dieser Phase wird jede zuvor definierte Frage als Ausgangspunkt genutzt, um gezielt nach relevanten Informationen zu suchen. Der Ablauf umfasst drei aufeinander abgestimmte Schritte:
- Websuche & Datenabruf
Die Frage wird in mehrere Web-Suchtools eingegeben. Die Inhalte der gefundenen Webseiten werden abgerufen und vorverarbeitet, um eine standardisierte Datenbasis zu schaffen. - Relevanzprüfung
Ein LLM-basierter Reviewer bewertet die Webseiteninhalte hinsichtlich ihrer Relevanz zur gestellten Frage. Irrelevante Quellen werden herausgefiltert. - Faktenblatt-Erstellung
Für jede relevante Webseite wird ein prägnantes Faktenblatt erstellt, das zentrale Informationen extrahiert und irrelevante Inhalte („Rauschen“) gezielt entfernt.
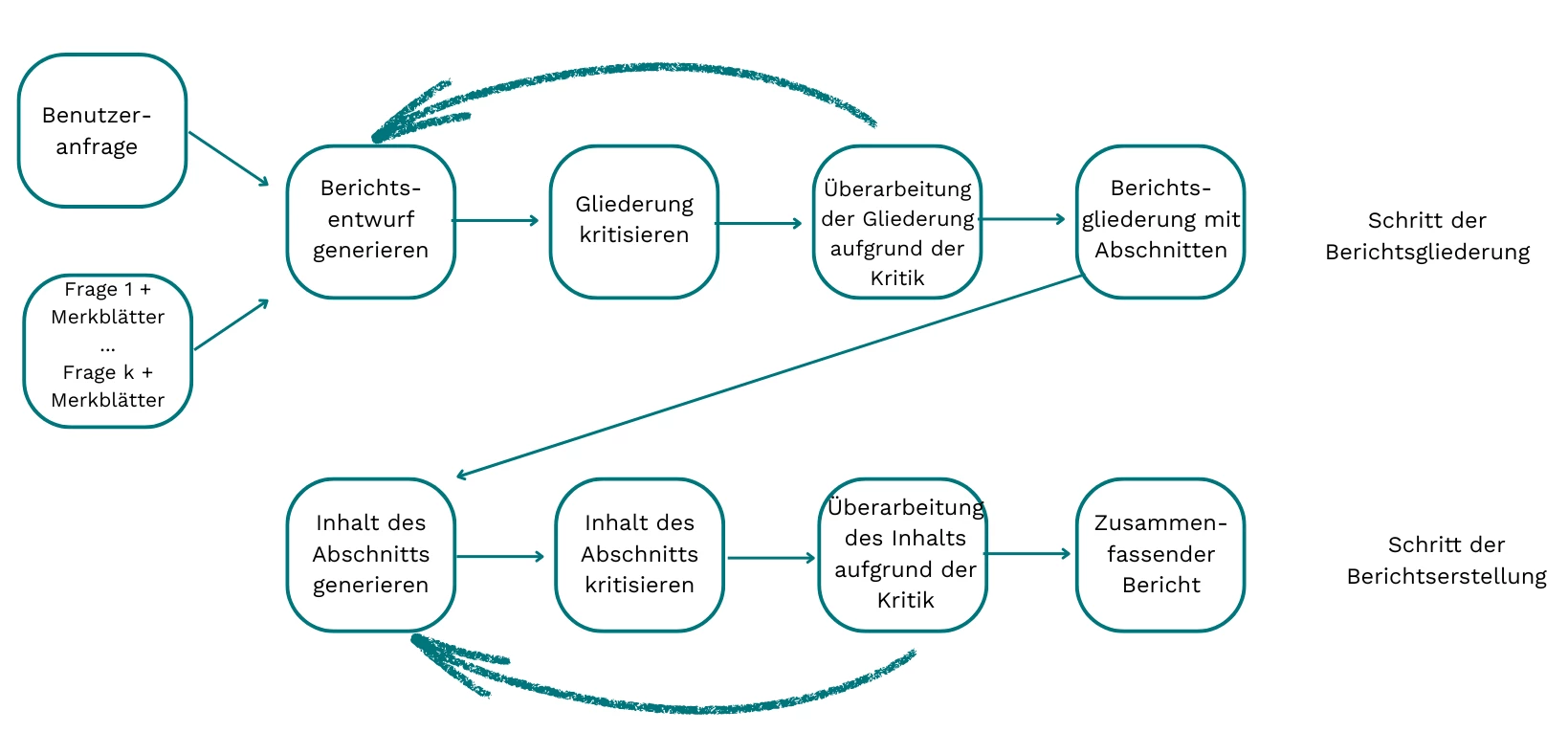
Phase 3: Komposition des Berichts
In der Kompositionsphase werden die Nutzeranfrage, die generierten Fragen sowie die zugehörigen Faktenblätter zusammengeführt, um einen strukturierten Marktforschungsbericht zu erstellen. Der Prozess ist in vier aufeinander abgestimmte Schritte gegliedert:
- Strukturierung des Entwurfs
Zunächst entsteht ein grober Berichtsentwurf mit Abschnittsüberschriften, den wichtigsten Inhalten pro Abschnitt sowie den zu zitierenden Quellen. Wie bereits in der Planungsphase kommt dabei ein Reflexionsansatz zum Einsatz, um Entwürfe gezielt zu optimieren. - Zusammenstellung der Referenzen
Aus den vorhandenen Faktenblättern werden relevante Quellen extrahiert und in einer standardisierten Referenzliste aufbereitet. - Ausformulierung der Inhalte
Jeder Abschnitt wird mit sorgfältig formulierten Texten gefüllt, die auf den gesammelten Fakten basieren und den inhaltlichen Kern präzise wiedergeben. - Finalisierung & Formatierung
Inhalte werden zusammengefasst, eine prägnante Gesamtsynopse erstellt und der Bericht inklusive Titel, Hauptteil und Referenzliste in ein einheitliches Format überführt.
Auswahl der Plattform und des Frameworks
Die Auswahl des richtigen Frameworks: Herausforderungen und Strategie
In der aktuellen agentenbasierten Phase der KI-Entwicklung erscheinen Open- und Closed-Source-Tools in rasantem Tempo. Viele Frameworks durchlaufen schnelle Iterationen, was es schwierig macht, den Überblick über neue Funktionen zu behalten. Die Entscheidung für ein passendes Tool muss dabei stets mit den strategischen Zielen des Unternehmens abgestimmt sein.
Unser Ansatz: praxisnah, ressourcenschonend, offen
Um ein realitätsnahes Szenario abzubilden, haben wir bewusst unter typischen Einschränkungen gearbeitet:
- Zeitrahmen: 4 Wochen
- Team: 2 Entwickler
- Technologie: ausschließlich Open-Source
Unsere Ziele:
- Aufbau einer vollständigen Plattform mit UI, API, Monitoring und Tracking
- Entwicklung einer Lösung, die wiederverwendbar, erweiterbar und auch für nichttechnische Nutzer:innen zugänglich ist – bei minimalem Supportbedarf
Unser Anspruch: Die Nutzung agentenbasierter Systeme im Unternehmen soll demokratisiert werden – durch einfache, unternehmensweite Zugänglichkeit.
Im nächsten Schritt werfen wir einen kurzen Blick auf führende Open-Source-Frameworks (Stand: 07.05.2025), die für solche Szenarien in Frage kommen.
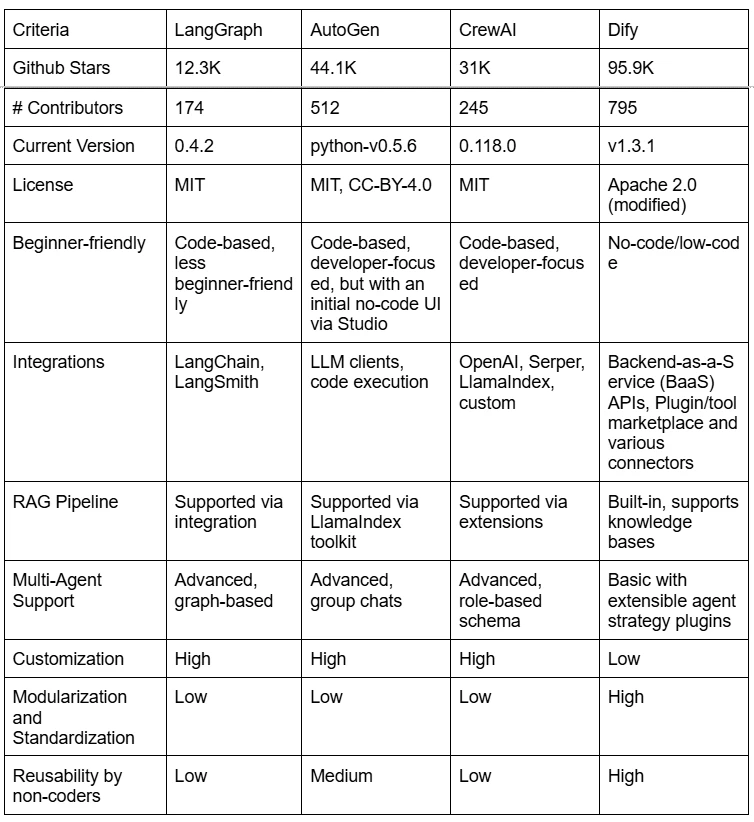
Warum wir uns für Dify entschieden haben
Basierend auf den zuvor genannten Anforderungen fiel unsere Wahl zunächst auf Dify – vor allem aufgrund seiner praktischen Vorteile:
- Intuitive Oberfläche: Auch für Nicht-Programmierer geeignet
- Integrierte Backend-APIs & UI: Ermöglicht schnelle Iterationen
- Schneller Einstieg: Ideal, um frühzeitig ein Gesamtbild zu erhalten und die beste Richtung für den konkreten Use Case zu erkennen
Ein weiterer Pluspunkt: Dify liegt bereits in Version 1.x mit Abwärtskompatibilität vor und weist laut GitHub-Community (Sterne & Mitwirkende) die größte Verbreitung unter vergleichbaren Open-Source-Frameworks auf.
Trotz des bekannten Risikos möglicher Lock-in-Effekte haben wir uns in diesem Fall bewusst für Dify entschieden – als pragmatischen, gut zugänglichen Startpunkt.
Was wir auf unserem Weg gelernt haben
Daten entscheiden über den Erfolg – wie auch bei RAG-Anwendungen
Wie bei allen Retrieval-Augmented-Generation-(RAG)-Ansätzen hängt die Qualität der Ergebnisse stark von den verwendeten Daten ab. Unser Marktforschungsagent nutzt öffentlich zugängliche Webinhalte – und stößt dabei auf typische Herausforderungen:
- Rauschen und Irrelevanz: Viele Webseiten enthalten Inhalte, die nicht zur gestellten Frage passen und daher gefiltert werden müssen.
- Unterschiedliche Datenmengen: Während manche Seiten nur wenige Zeilen liefern, enthalten andere seitenlange Geschäftsberichte. Diese großen Textmengen müssen gezielt verarbeitet werden, um relevante Inhalte herauszufiltern.
Unser Ansatz:
Wir nutzen große Sprachmodelle (LLMs), um irrelevante Inhalte automatisch auszuschließen. Bei sehr umfangreichen Quellen erstellen wir kompakte Faktenblätter, die die zentralen Informationen auf den Punkt bringen – als Grundlage für fundierte und präzise Reports.
Modellleistung vs. Workflow-Komplexität
Während der Entwicklungsphase haben wir selbst gehostete LLMs über Ollama eingesetzt, um Kosten zu senken – denn Agentenlösungen erzeugen einen hohen Token-Verbrauch.
Dabei wurde schnell klar:
- Je weniger leistungsfähig ein Modell ist, desto stärker muss der Workflow gesteuert werden.
- In frühen Tests zeigten schwächere Modelle die Tendenz, vom ursprünglichen Prompt abzuweichen und sich durch irrelevante Ergebnisse ablenken zu lassen. Die Wahl des richtigen LLMs beeinflusst daher maßgeblich das Design des gesamten Prozesses.
Diese Erkenntnis war ein Hauptgrund, größere Aufgaben in kleinere Teilaufgaben zu zerlegen – inklusive des Einsatzes von LLM-basierten „Kritikern“, um die Qualität in jedem Schritt zu sichern.
Automatisierte Bewertung und Transparenz von Anfang an
Je komplexer ein Agentenprozess ist, desto wichtiger ist vollständige Nachvollziehbarkeit. Viele Komponenten greifen ineinander – ein Fehler kann das gesamte System stören. Deshalb haben wir von Anfang an umfassendes Tracing im Workflow integriert.
Die Entwicklung eines Agenten eröffnet viele Gestaltungsoptionen: von der Wahl der Websuche über Prompt-Strategien bis hin zu Agenten-Patterns. Eine manuelle Prüfung jedes Berichts ist zu aufwendig – daher braucht es automatisierte Auswertungen. Wir haben dafür zwei Evaluatoren entwickelt:
- Completeness Evaluator: Bewertet die Vollständigkeit eines generierten Reports anhand einer verifizierten Marktstudie als Referenz.
- Groundedness Evaluator: Überprüft, ob Aussagen im Report durch konkrete Quellen (z. B. URLs) belegt und durch die Inhalte dieser Seiten tatsächlich gestützt werden. Diese Prüfung erfolgt durch einen weiteren Agenten mit Webzugang.
Reflexion über den Einsatz von Dify
Plattformen wie Dify haben das Potenzial, in der agentenbasierten Ära eine ähnliche Rolle einzunehmen wie Microsoft Word im Office-Bereich. Sie ermöglichen auch Nicht-Entwicklern, komplexe Aufgaben umzusetzen – ohne eigene Codezeilen schreiben zu müssen.
Doch wie bei vielen No-Code- und Low-Code-Lösungen gilt: Der einfache Zugang bringt auch strukturelle Grenzen mit sich, insbesondere für erfahrene Entwicklern. Dazu zählen:
- Vordefinierte Module: Die feste Trennung zwischen Chatflows (Orchestrierung) und Workflows (wiederverwendbare Bausteine) schränkt die Flexibilität bei komplexeren Anwendungsfällen ein.
- Eingeschränkte Codeblöcke: Kleine, isolierte Code-Segmente ohne IDE-Unterstützung erschweren das effiziente Arbeiten.
- Automatisierte Prüfmechanismen: Bestimmte Designs, Datentypen oder Outputs werden automatisch blockiert – ein anderer Umgang mit Fehlern als bei klassischen Unit-Tests.
- Kollaborationsgrenzen: Funktionen wie Versionskontrolle oder GitHub-ähnliche Zusammenarbeit sind nicht nativ integriert.
- Framework-spezifische Einschränkungen, zum Beispiel:
- Kein direktes Kopieren von Blöcken zwischen Workflows
- JSON-Ausgaben müssen manuell geprüft werden
- Verschachtelte Iterationen erfordern separate Tools
Auch für Nicht-Coder gilt: Ein Grundverständnis für Variablentypen, Kontrollstrukturen oder Iterationen ist hilfreich. Um den Einstieg zu erleichtern und die Plattform effektiv zu nutzen, empfehlen wir gezielte Onboarding-Workshops.
Sie möchten mehr über das Thema erfahren? Lesen Sie unser Whitepaper über generative KI-Agenten in Aktion.