
Introduction
Generative AI agents (GenAIagents) bear the potential to automate intricate reasoning tasks, decision-making processes, and multimodal interactions across diverse domains, including customer support, software development, knowledge retrieval, and autonomous workflow orchestration.
These agents possess advanced reasoning capabilities that enable them to plan and reflect, as well as short- and long-term memory functions that allow them to recall previous interactions. Furthermore, they are capable of leveraging external tools, such as calculators or web searches, to enhance their performance.
What is a Market Research Agent?
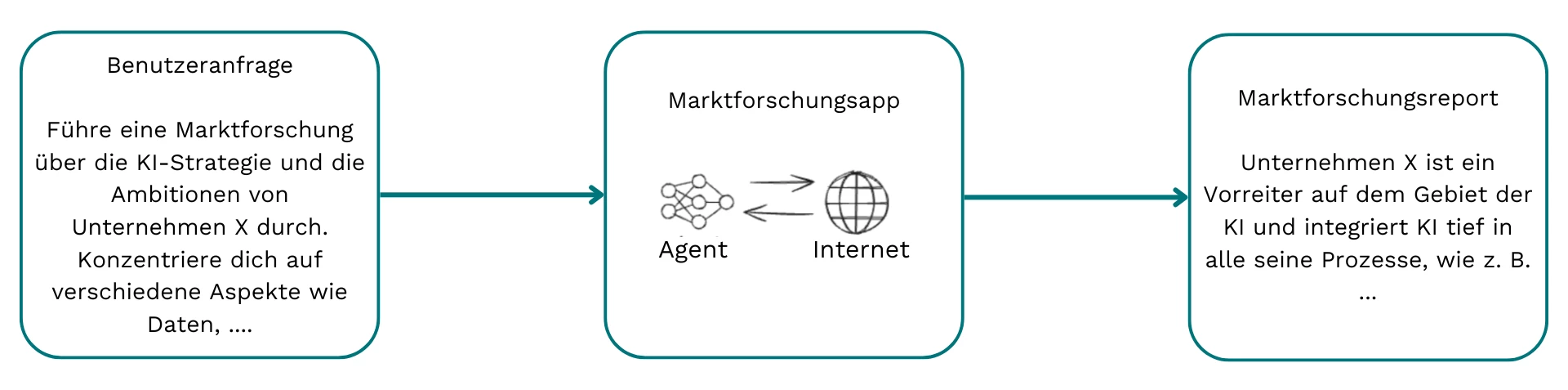
A market research agent can be viewed as a specialized variant of a deep research agent, such as those provided by companies like OpenAI, Perplexity, and Jina AI. The agent takes a query as input, for example:
Conduct a market research analysis on the AI strategy and ambitions of company X, focusing on various aspects including data…”
It then performs an extensive web search until it gathers sufficient information to compile a comprehensive market research report that fulfills the user request.
A market research agent must possess multiple capabilities to succeed:
- The agent needs to comprehend the user’s request and devise a plan
- The agent must:
- Reason about what information is required and conductcorresponding web search queries, as well as
- Assess the relevance of obtained web search results and determine possible follow-up queries.
- To achieve this, the agent must remain goal-focused, keeping track of the initial user request in mind and steering its behaviour towards generating the final market research report.
- Furthermore, it is essential that the agent avoids providing unsubstantiated claims and instead grounds its claims and findings in verifiable sources, providing citations as necessary.
Based on these considerations, we adopted a divide-and-conquer approach, which is outlined in the following section.
Our Approach: Divide-and-Conquer
We followed a divide-and-conquer approach where we reduced the overall complexity of the task into three smaller building blocks that will be handled separately:
- Elaborating & Planning: Based on the user’s request, we refine the original query, expand upon it, and compile a comprehensive list of questions that need to be addressed in order to fulfill the user's requirements effectively.
- Deep Search: For each question generated during the elaborating and planning stage, we conduct multiple web searches utilizing various tools to gather information from diverse sources. Based on the collected data, we compile a list of fact sheets that include key quotes and relevant metadata.
- Composing: We compile all fact sheets produced during the deep search stage to create a report outline, which ultimately informs the development of a comprehensive market research report. This report is structured into distinct sections and includes a detailed reference list.

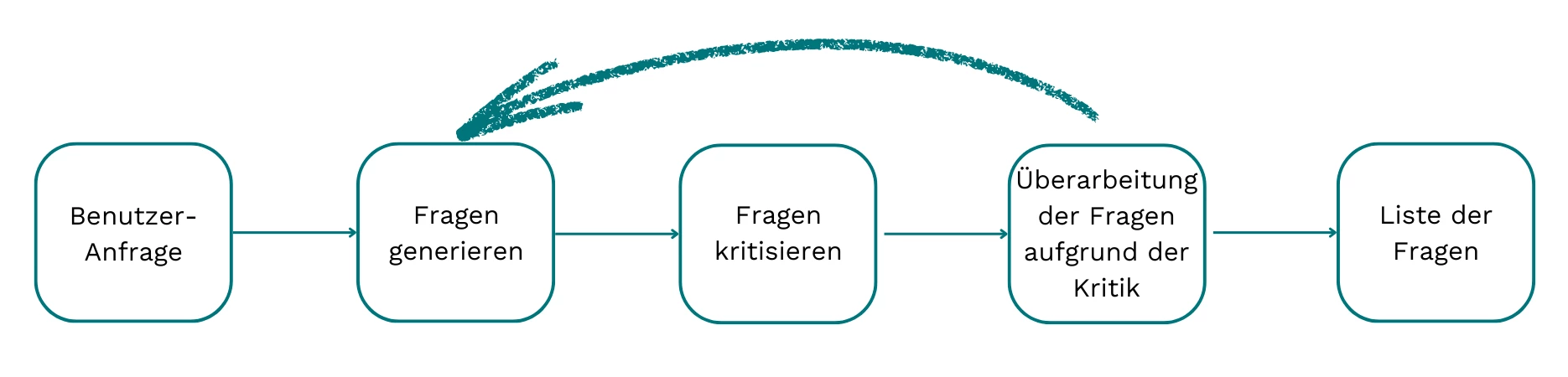
Elaborating & Planning Stage
The elaborating & planning stage aims to generate a list of key questions that are crucial for fulfilling the user’s request. Overall, it closely follows the reflection pattern, with potentially multiple iterations. In each iteration, the process begins with advanced copyediting of the original query to enhance its clarity, grammar, coherence, precision, and overall readability, ultimately better capturing the user's intent and context. The original question is then expanded into business-oriented research questions that directly address all relevant topics and underlying concepts present in the user's query, laying the groundwork for critical analysis and in-depth exploration. Finally, these questions are prioritized according to their importance to the original user query, allowing for adaptation if the user limits the maximum number of questions.
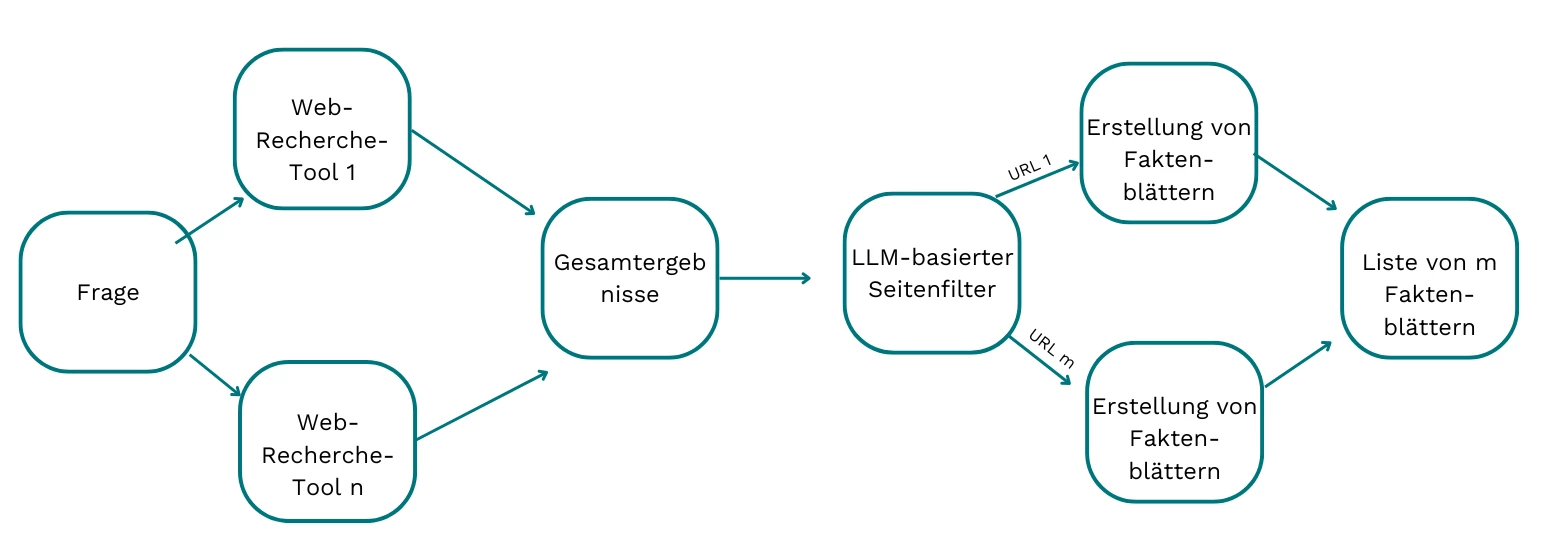
Deep Search Stage
In the deep search stage, a generated question from the elaborating and planning stage is taken as input, and the following steps are performed:
- Enter the question into multiple web search tools, and then retrieve and process the raw content from the resulting web pages to produce standardized output.
- Filter out irrelevant web pages based on an LLM-reviewer that classifies the relevance of a web page based on the question
- Create a concise fact sheet for each unfiltered webpage, effectively distilling relevant information and eliminating unnecessary noise from the content
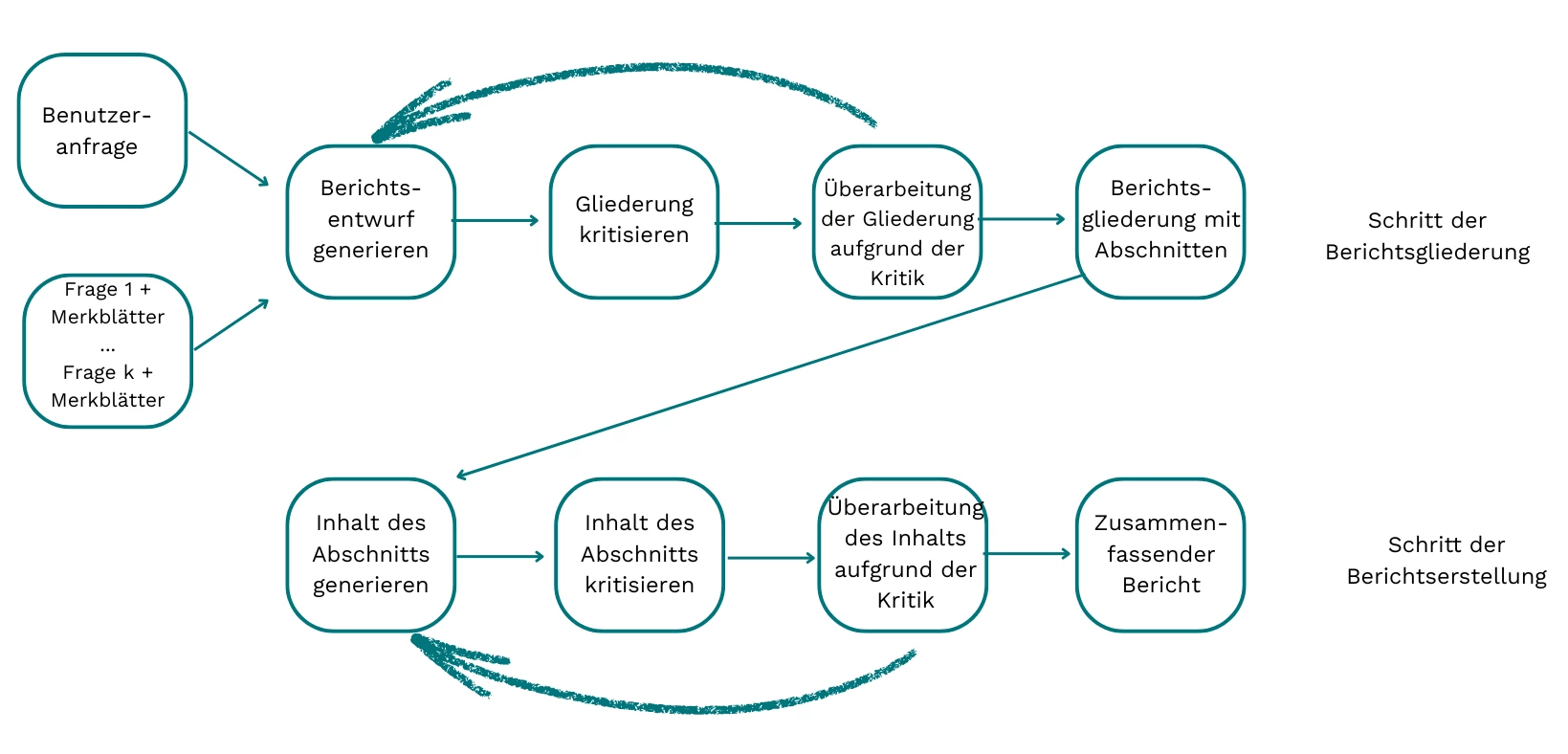
Composing Stage
Lastly, the composing stage takes in the user request, the generated questions along with their corresponding fact sheets, and produces a comprehensive marketing report. In keeping with our complexity reduction strategy, the composing stage involves four key steps:
- Create a comprehensive report outline, including section headings, key points to be addressed in each section, and relevant sources to be cited. As in the elaborating and planning stage, we utilize the reflection pattern to refine our initial drafts.
- Extract relevant reference information from the provided fact sheets and compile it into a reference list, adhering to the designated format.
- Generate the final report contents, where each section is thoroughly fleshed out with detailed content that is meticulously grounded in the provided fact sheets.
- Compile the contents of the generated report sections together, create an abstract based on all generated contents, and then combine the title, abstract, main body of the report, and reference list into a cohesive document using a predefined format template.
Platform & Framework Selection
In this agentic era, a plethora of open- and closed-source tools, frameworks, and platforms are proliferating and emerging at an unprecedented rate. Choosing between different frameworks can be a daunting task, as these tools are often in a state of constant development and undergo swift iterations, making it challenging to keep pace with the latest features. Furthermore, such decisions must be aligned with the company's strategic objectives at any given time.
In our scenario, several key considerations come into play. To simulate real-world situations found in many companies, we aim to maximize results while minimizing resources. Therefore, we have imposed a constraint of a tight deadline of just under one month, only two available developers, and relying on only open-source frameworks. Despite these limitations, we hope to achieve two primary objectives. On the one hand, we strive to develop a fully-fledged platform featuring frontend and backend UIs, APIs, monitoring, and tracking mechanisms. On the other hand, we envision a solution that is not only easily reusable and extensible but also accessible and adjustable by non-technical staff across the company, requiring minimal engineering support. Ultimately, our goal is to democratize agent usage throughout the organization, making it more widely available and user-friendly.
With these factors in mind, let's take a brief look at some of the most prominent open-source frameworks available at the moment (as of 07.05.2025).
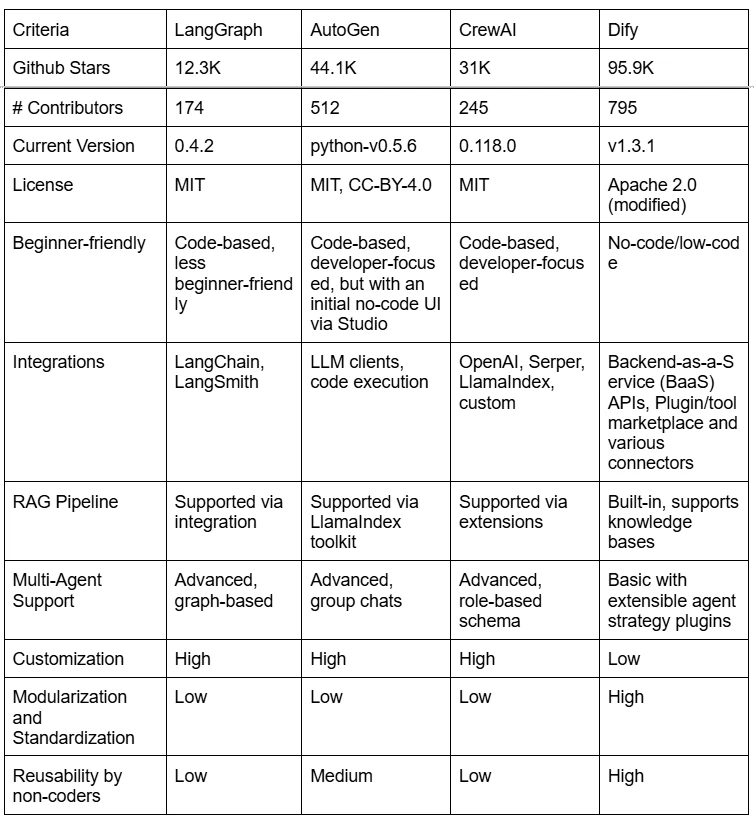
Given the considerations mentioned earlier, trying out Dify first appears to be a reasonable decision. It offers a user-friendly interface for non-coders, along with built-in backend APIs and UI. This allows for rapid iteration at a coarse level initially, helping us grasp the big picture before narrowing down on the most promising direction for the specific use case. Meanwhile, Dify is already in version 1.x with backward compatibility and has the largest community based on GitHub stars and contributors. While any framework we choose may come with the risk of lock-in, we’ve opted for Dify in this case.
What We Have Learned Along the Way
Data Is Key — Always
Like all retrieval-augmented generation (RAG) applications, the quality of the data used is crucial for achieving optimal outputs. Since the market research agent leverages RAG on the internet, it inevitably encounters the same challenges inherent to RAG.
- Retrieved information can be noisy and irrelevant: Numerous web pages feature content that must be meticulously filtered out,
- Retrieved information can be large and extensive: whereas some web pages may contain only a single paragraph, others may feature lengthy annual reports that are large in size, resulting in enormous contexts that need to be processed during the report composing stage.
We mitigated the noise issue by using LLMs to filter out web contents that are irrelevant for the question at hand. For extensive and large web pages, we utilize LLMs to create concise fact sheets that extract and present only the essential information necessary for answering the question.
Balancing Model Capability and Workflow Complexity
We utilized self-hosted LLMs via Ollama during initial development to reduce costs, as agent applications involve a substantial amount of token usage.
Notably, the less capable the model, the more steering is required to stay on track during the market research task. In our initial attempts, we observed that weaker models often deviated from the original user request and became sidetracked by irrelevant search results. Consequently, the choice of LLM can significantly impact workflow design decisions.
→ The less capable the model, the more intricate and tightly controlled the workflow must be.
This was one of the key motivations behind breaking down larger tasks into smaller components, leveraging LLM critics and thereby guaranteeing a higher quality output at each stage.
Automatic Evaluation and Observability from Day 1
- The more complex a task is and the more steps are required, the greater the importance of ensuring a proper observability at every stage. With numerous components that can potentially disrupt the entire system, it is essential to implement comprehensive tracing of the workflow from the outset.
- Building an agent unlocks a wide range of possibilities, including the selection of various web search tools, prompts, and agent patterns. Manually inspecting every research report in-depth is a labor-intensive task, making automated evaluations critical. To address this need, we developed two evaluators:
- Completeness Evaluator: This utilizes a ground-truth market research summary as an anchor to assess the completeness of the generated report.
- Groundedness Evaluator: The groundedness evaluator validates the claims made in the generated report by verifying whether they are supported by citations (in the form of URL links) and if these claims are substantiated by the contents of the respective URL pages. Since this evaluation necessitates the examination of URL contents, it is facilitated by another agent that is equipped with a web search tool.
Reflections on Dify
Tools similar to Dify could potentially become the "Microsoft Word" in this agentic era, enabling even beginners to easily accomplish tasks. However, as with all no-code/low-code solutions, such platforms can also be a double-edged sword, where the same advantages may also pose challenges, especially for developers used to coding.
- Standardized modules and blocks: Developers accustomed to high levels of customizability and freedom may find it challenging to adapt to the framework’s specific logic. For example, understanding distinctions between Chatflows (orchestrator-level apps) and Workflows (atomic reusable tools) can be difficult.
- Code block limitations: Developers may find it awkward to work within small, predefined code blocks without typical IDE supports and gadgets.
- Automatic blocking: The platform prevents non-conforming design choices, variable types, or outputs, which differs from traditional unit or integration testing.
- Collaboration limitations: GitHub-style versioning and collaboration are not inherently designed for this platform.
- Other framework-specific limitations, for example:
- Unable to directly copy blocks across workflows.
- Output JSON format from different tools often needs to be checked.
- Nested iteration requires converting the first layer of iteration into a tool.
Additionally, non-coders may need to grasp basic coding concepts like variable types and iterations to adapt to the constraints of such platforms. Therefore, dedicated onboarding workshops are essential to ease the learning curve and ensure a smooth user experience.
You want to know more about the topic? Read our Whitepaper about Generative AI Agents in Action.